Cross-perspective Topic Modeling
CR
An application that uses cross-perspective topic modeling to extract topics and opinions from text and provides insight into how they change over time.
Updated 49 months ago
11 3
Making harmonisation simple. Social scientists often have to compare items from different questionnaires or datasets. Harmony is a tool that uses natural language processing and generative AI models to help researchers harmonise questionnaire items quickly, even in different languages.
Do you need to compare questionnaire items across studies? Do you want to find the best match for a set of items? Are there are different versions of the same questionnaire floating around and you want to make sure how compatible they are? Are the questionnaires written in different languages that you would like to compare?
Here's a walkthrough video on how you can use Harmony online at harmonydata.ac.uk. Click to view:

The Harmony project is a data harmonisation project that uses Natural Language Processing to help researchers make better use of existing data from different studies by supporting them with the harmonisation of various measures and items used in different studies. Harmony is a collaboration project between Ulster University, University College London, the Universidade Federal de Santa Maria, and Fast Data Science. Harmony is funded by Wellcome as part of the Wellcome Data Prize in Mental Health.
Harmony is a project in active development and you can contribute.
If you have found a bug or would like a new feature, you can raise an issue here for issues with Harmony's natural language understanding functionality, or alternatively here for issues with Harmony's user interface and graphics. You can also join our Discord server!
Read our guide to contributing to Harmony here or read CONTRIBUTING.md.
You can run the walkthrough Python notebook in Google Colab with a single click:
You can also download an R markdown notebook to run in R Studio:
You can run the walkthrough R notebook in Google Colab with a single click:
Harmony is a tool using AI which allows you to compare items from questionnaires and identify similar content. You can try Harmony at https://harmonydata.ac.uk/app and you can read our blog at https://harmonydata.ac.uk/blog/.
You can contact Harmony team at https://harmonydata.ac.uk/, or Thomas Wood at https://fastdatascience.com/.
Visit: https://harmonydata.ac.uk/app/
You can also visit our blog at https://harmonydata.ac.uk/
Download and install Java if you don't have it already. Download and install Apache Tika and run it on your computer https://tika.apache.org/download.html
java -jar tika-server-standard-2.3.0.jar
You need a Windows, Linux or Mac system with
You can install from PyPI.
pip install harmonydata
Harmony uses spaCy to help with text extraction from PDFs. spaCy models can be downloaded with the following command in Python:
import harmony
harmony.download_models()
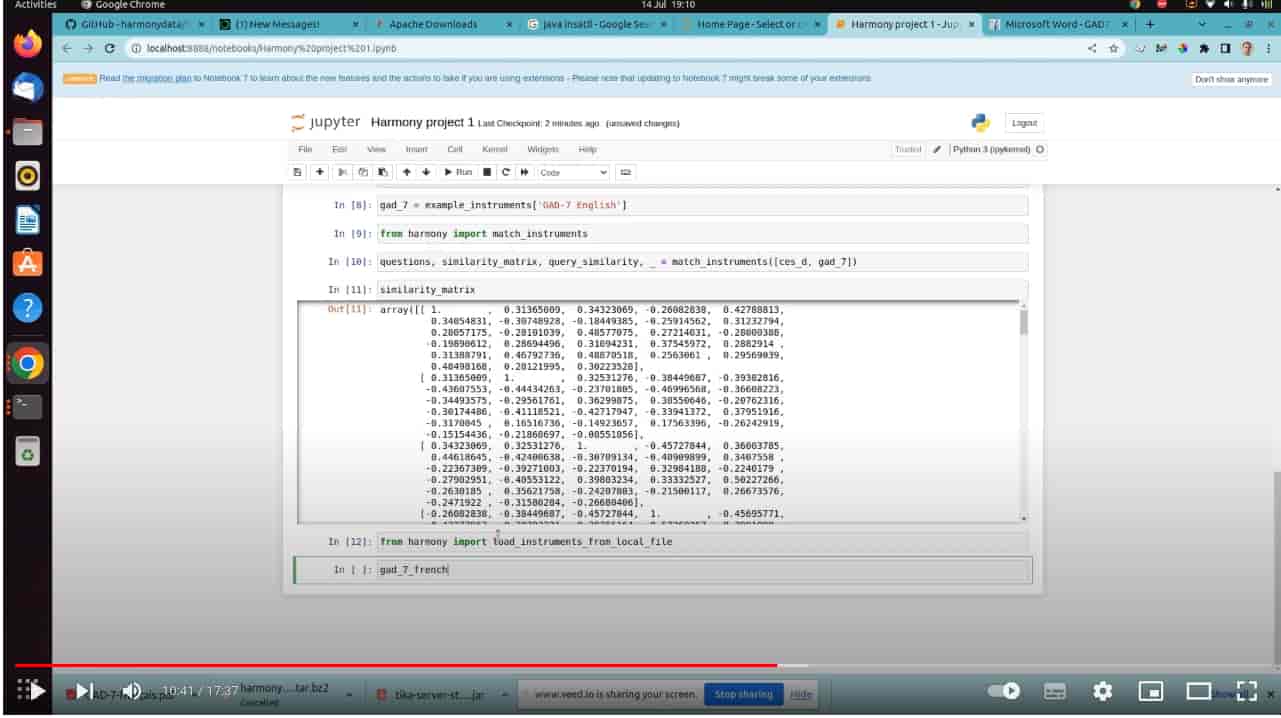
instruments = harmony.example_instruments["CES_D English"], harmony.example_instruments["GAD-7 Portuguese"]
questions, similarity, query_similarity, new_vectors_dict = harmony.match_instruments(instruments)
harmony.load_instruments_from_local_file("gad-7.pdf")

In 2023, the Australian Data Archive (ADA) i embarked on a project to harmonise a vast collection of survey questions, seeking a solution that could effectively identify and group similar items across different studies. Researchers at the ADA found Harmony, a data harmonisation tool powered by natural language processing (NLP), and the ADA recognised its potential to streamline this process. https://harmonydata.ac.uk/ada/
Using Natural Language processing for faster Data Harmonization and easier Data discoverability
Five umc's - UMC Utrecht, Radboudumc, UMCG, ErasmusMC and AmsterdamUMC - work together to (co-)develop open source solutions, and validate our methods and techniques with each other, for the (re)use of free medical text present in our EHRs.
Diversity-aware language technology for conversational data
An Artificial Intelligence Approach to Comparing Text Versions
Facilitating and supporting large-scale text mining in the field of digital humanities
An application that uses cross-perspective topic modeling to extract topics and opinions from text and provides insight into how they change over time.
Deep Insight And Neural Network Analysis, DIANNA is the only Explainable AI, XAI library for scientists supporting Open Neural Network Exchange, ONNX - the de facto standard models format.
A flexible solution to build text mining workflows that allows you to quickly combine Natural Language Processing tools from different sources.
A visualization that shows how the meaning we attach to a given concept shifts over time.
Texcavator is a search engine and text mining application for creating word cloud and time line visualizations of large text corpora.
the eXtensible Text Analysis Suite