Get started
345 commitsLast commit ≈ 3 months ago471 stars41 forks
Interpretability for sequence generation models 🐛 🔍





Inseq is a Pytorch-based hackable toolkit to democratize access to common post-hoc interpretability analyses of sequence generation models.
Inseq is available on PyPI and can be installed with pip for Python >= 3.10, <= 3.13:
# Install latest stable version
pip install inseq
# Alternatively, install latest development version
pip install git+https://github.com/inseq-team/inseq.git
Install extras for visualization in Jupyter Notebooks and 🤗 datasets attribution as pip install inseq[notebook,datasets].
cd inseq
make uv-download # Download and install the uv package manager
make install # Installs the package and all dependencies via uv sync
For library developers, you can use the make install-dev command to install all development dependencies (quality, docs, extras).
After installation, you should be able to run make fast-test and make lint without errors.
Installing the tokenizers package requires a Rust compiler installation. You can install Rust from https://rustup.rs and add $HOME/.cargo/env to your PATH.
Installing sentencepiece requires various packages, install with sudo apt-get install cmake build-essential pkg-config or brew install cmake gperftools pkg-config.
This example uses the Integrated Gradients attribution method to attribute the English-French translation of a sentence taken from the WinoMT corpus:
import inseq
model = inseq.load_model("Helsinki-NLP/opus-mt-en-fr", "integrated_gradients")
out = model.attribute(
"The developer argued with the designer because her idea cannot be implemented.",
n_steps=100
)
out.show()
This produces a visualization of the attribution scores for each token in the input sentence (token-level aggregation is handled automatically). Here is what the visualization looks like inside a Jupyter Notebook:
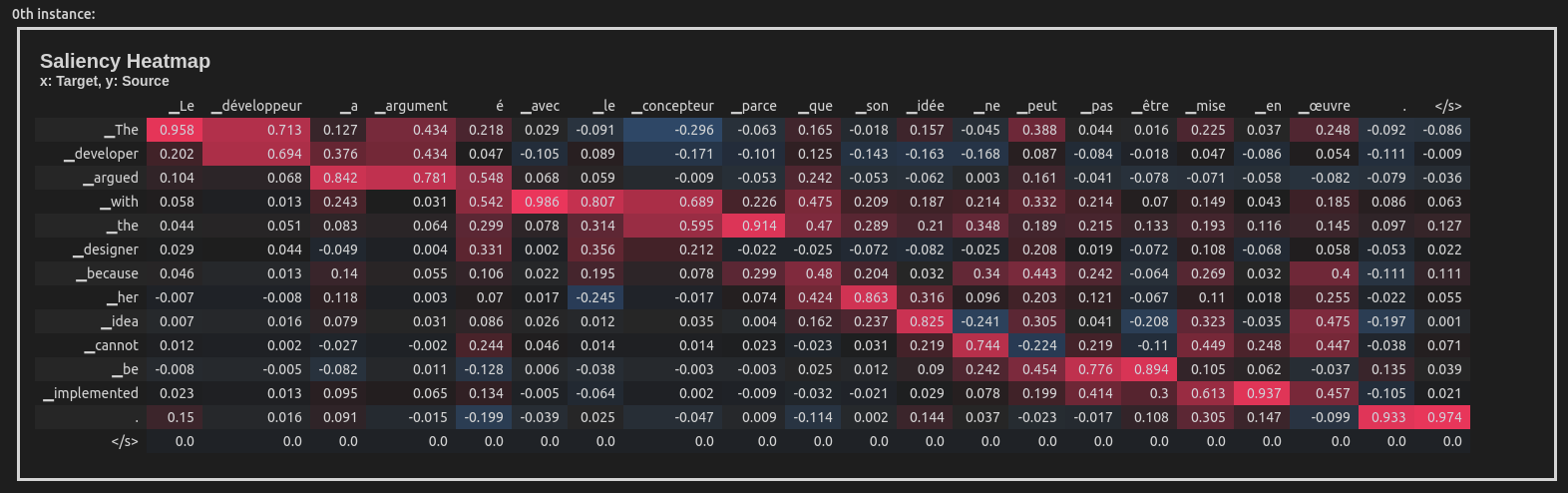
Inseq also supports decoder-only models such as GPT-2, enabling usage of a variety of attribution methods and customizable settings directly from the console:
import inseq
model = inseq.load_model("gpt2", "integrated_gradients")
model.attribute(
"Hello ladies and",
generation_args={"max_new_tokens": 9},
n_steps=500,
internal_batch_size=50
).show()

🚀 Feature attribution of sequence generation for most ForConditionalGeneration (encoder-decoder) and ForCausalLM (decoder-only) models from 🤗 Transformers
🚀 Support for multiple feature attribution methods, extending the ones supported by Captum
🚀 Post-processing, filtering and merging of attribution maps via Aggregator classes.
🚀 Attribution visualization in notebooks, browser and command line.
🚀 Efficient attribution of single examples or entire 🤗 datasets with the Inseq CLI.
🚀 Custom attribution of target functions, supporting advanced methods such as contrastive feature attributions and context reliance detection.
🚀 Extraction and visualization of custom scores (e.g. probability, entropy) at every generation step alongsides attribution maps.
Use the inseq.list_feature_attribution_methods function to list all available method identifiers and inseq.list_step_functions to list all available step functions. The following methods are currently supported:
saliency: Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps (Simonyan et al., 2013)
input_x_gradient: Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps (Simonyan et al., 2013)
integrated_gradients: Axiomatic Attribution for Deep Networks (Sundararajan et al., 2017)
deeplift: Learning Important Features Through Propagating Activation Differences (Shrikumar et al., 2017)
gradient_shap: A unified approach to interpreting model predictions (Lundberg and Lee, 2017)
discretized_integrated_gradients: Discretized Integrated Gradients for Explaining Language Models (Sanyal and Ren, 2021)
sequential_integrated_gradients: Sequential Integrated Gradients: a simple but effective method for explaining language models (Enguehard, 2023)
attention: Attention Weight Attribution, from Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al., 2014)occlusion: Visualizing and Understanding Convolutional Networks (Zeiler and Fergus, 2014)
lime: "Why Should I Trust You?": Explaining the Predictions of Any Classifier (Ribeiro et al., 2016)
value_zeroing: Quantifying Context Mixing in Transformers (Mohebbi et al. 2023)
reagent: ReAGent: A Model-agnostic Feature Attribution Method for Generative Language Models (Zhao et al., 2024)
Step functions are used to extract custom scores from the model at each step of the attribution process with the step_scores argument in model.attribute. They can also be used as targets for attribution methods relying on model outputs (e.g. gradient-based methods) by passing them as the attributed_fn argument. The following step functions are currently supported:
logits: Logits of the target token.probability: Probability of the target token. Can also be used for log-probability by passing logprob=True.entropy: Entropy of the predictive distribution.crossentropy: Cross-entropy loss between target token and predicted distribution.perplexity: Perplexity of the target token.contrast_logits/contrast_prob: Logits/probabilities of the target token when different contrastive inputs are provided to the model. Equivalent to logits/probability when no contrastive inputs are provided.contrast_logits_diff/contrast_prob_diff: Difference in logits/probability between original and foil target tokens pair, can be used for contrastive evaluation as in contrastive attribution (Yin and Neubig, 2022).pcxmi: Point-wise Contextual Cross-Mutual Information (P-CXMI) for the target token given original and contrastive contexts (Yin et al. 2021).kl_divergence: KL divergence of the predictive distribution given original and contrastive contexts. Can be restricted to most likely target token options using the top_k and top_p parameters.in_context_pvi: In-context Pointwise V-usable Information (PVI) to measure the amount of contextual information used in model predictions (Lu et al. 2023).mc_dropout_prob_avg: Average probability of the target token across multiple samples using MC Dropout (Gal and Ghahramani, 2016).top_p_size: The number of tokens with cumulative probability greater than top_p in the predictive distribution of the model.The following example computes contrastive attributions using the contrast_prob_diff step function:
import inseq
attribution_model = inseq.load_model("gpt2", "input_x_gradient")
# Perform the contrastive attribution:
# Regular (forced) target -> "The manager went home because he was sick"
# Contrastive target -> "The manager went home because she was sick"
out = attribution_model.attribute(
"The manager went home because",
"The manager went home because he was sick",
attributed_fn="contrast_prob_diff",
contrast_targets="The manager went home because she was sick",
# We also visualize the corresponding step score
step_scores=["contrast_prob_diff"]
)
out.show()
Refer to the documentation for an example including custom function registration.
The Inseq library also provides useful client commands to enable repeated attribution of individual examples and even entire 🤗 datasets directly from the console. See the available options by typing inseq -h in the terminal after installing the package.
Three commands are supported:
inseq attribute: Wrapper for enabling model.attribute usage in console.
inseq attribute-dataset: Extends attribute to full dataset using Hugging Face datasets.load_dataset API.
inseq attribute-context: Detects and attribute context dependence for generation tasks using the approach of Sarti et al. (2023).
All commands support the full range of parameters available for attribute, attribution visualization in the console and saving outputs to disk.
The following example performs a simple feature attribution of an English sentence translated into Italian using a MarianNMT translation model from transformers. The final result is printed to the console.
inseq attribute \
--model_name_or_path Helsinki-NLP/opus-mt-en-it \
--attribution_method saliency \
--input_texts "Hello world this is Inseq\! Inseq is a very nice library to perform attribution analysis"
The following code can be used to perform attribution (both source and target-side) of Italian translations for a dummy sample of 20 English sentences taken from the FLORES-101 parallel corpus, using a MarianNMT translation model from Hugging Face transformers. We save the visualizations in HTML format in the file attributions.html. See the --help flag for more options.
inseq attribute-dataset \
--model_name_or_path Helsinki-NLP/opus-mt-en-it \
--attribution_method saliency \
--do_prefix_attribution \
--dataset_name inseq/dummy_enit \
--input_text_field en \
--dataset_split "train[:20]" \
--viz_path attributions.html \
--batch_size 8 \
--hide
The following example uses a small LM to generate a continuation of input_current_text, and uses the additional context provided by input_context_text to estimate its influence on the the generation. In this case, the output "to the hospital. He said he was fine" is produced, and the generation of token hospital is found to be dependent on context token sick according to the contrast_prob_diff step function.
inseq attribute-context \
--model_name_or_path HuggingFaceTB/SmolLM-135M \
--input_context_text "George was sick yesterday." \
--input_current_text "His colleagues asked him to come" \
--attributed_fn "contrast_prob_diff"
Result:
Our vision for Inseq is to create a centralized, comprehensive and robust set of tools to enable fair and reproducible comparisons in the study of sequence generation models. To achieve this goal, contributions from researchers and developers interested in these topics are more than welcome. Please see our contributing guidelines and our code of conduct for more information.
If you use Inseq in your research we suggest including a mention of the specific release (e.g. v0.6.0) and we kindly ask you to cite our reference paper as:
@inproceedings{sarti-etal-2023-inseq,
title = "Inseq: An Interpretability Toolkit for Sequence Generation Models",
author = "Sarti, Gabriele and
Feldhus, Nils and
Sickert, Ludwig and
van der Wal, Oskar and
Nissim, Malvina and
Bisazza, Arianna",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-demo.40",
doi = "10.18653/v1/2023.acl-demo.40",
pages = "421--435",
}
Inseq has been used in various research projects. A list of known publications that use Inseq to conduct interpretability analyses of generative models is shown below.
[!TIP] Last update: August 2024. Please open a pull request to add your publication to the list.
